Automatic Extraction of Metadata - FileHold Document Management Software
Document Management Software is a secure central repository for an organization’s documents. The repository is searchable via a full text search of the document but more importantly can be searched, sorted and classified according to metadata (data about data) collected relative to the document. Most document creation tools ( i.e. word or PDF) automatically, or allows users, to add “properties” to the document. These properties include information like the date the document was created, author name, subject matter etc.
Ideally, when this document was added to the repository, these properties would become the metadata of the document. FileHold document management software can be configured to do this automatically. This automatic capture of metadata saves users time when adding documents to the library and moreover enhances search and usability of the document at a later date.
How it is Done The properties of a document can be automatically extracted into metadata fields for a defined schema (Schema – the definition of the document type i.e. research report) when an extraction rule for that document type is configured. All document types have properties, making it possible to extract metadata from any type of document. This is useful for file types such as images where you can extract information such as the size of the picture, the camera type, exposure time, resolution, and so on directly from the image file.
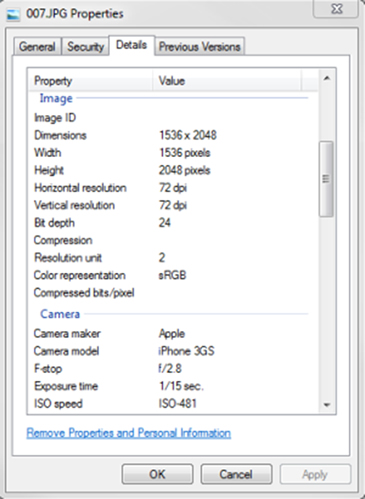
The document properties are taken from the “Details” tab of the document properties which can be viewed from Microsoft Windows Explorer. These properties may vary for each document type and in operating systems such as Windows XP or Windows 7. The example below shows some of the file properties of an image file within Windows Explorer in Windows 7.
Ideally, when this document was added to the repository, these properties would become the metadata of the document. FileHold document management software can be configured to do this automatically. This automatic capture of metadata saves users time when adding documents to the library and moreover enhances search and usability of the document at a later date.
How it is Done The properties of a document can be automatically extracted into metadata fields for a defined schema (Schema – the definition of the document type i.e. research report) when an extraction rule for that document type is configured. All document types have properties, making it possible to extract metadata from any type of document. This is useful for file types such as images where you can extract information such as the size of the picture, the camera type, exposure time, resolution, and so on directly from the image file.
The document properties are taken from the “Details” tab of the document properties which can be viewed from Microsoft Windows Explorer. These properties may vary for each document type and in operating systems such as Windows XP or Windows 7. The example below shows some of the file properties of an image file within Windows Explorer in Windows 7.
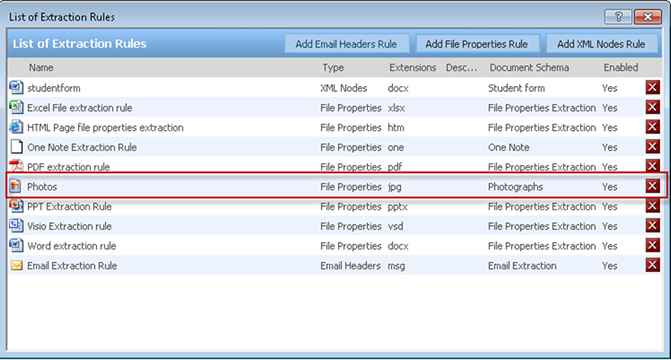
When creating extraction rules for documents, you can create an extraction rule for each type of document that you want to extract values from. For example, you can set a separate rule for a docx, xlsx, pdf, jpg, tiff, and so on. You can create several extraction rules per document extension; however, only one extraction rule per document extension can be enabled at a time. The example below shows a rule created for photographs with the jpg document type.
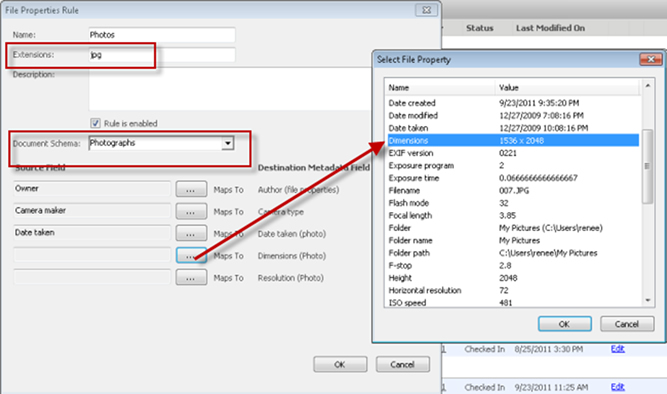
When creating a document properties rule, document "template" is selected. A document template is simply any document with the document type that you want to extract metadata from. The document template used will determine the type of document property extraction rule created; it is dependent on the document type such as a docx, xlsx, pdf, jpg and so forth. For example, to create a jpg document extraction rule, select a jpg document as the template.
A document schema is also assigned to the rule and the metadata fields are mapped to the document properties. In the example below, an extraction rule was created for an image document (jpg) file type using the Photographs schema.
A document schema is also assigned to the rule and the metadata fields are mapped to the document properties. In the example below, an extraction rule was created for an image document (jpg) file type using the Photographs schema.
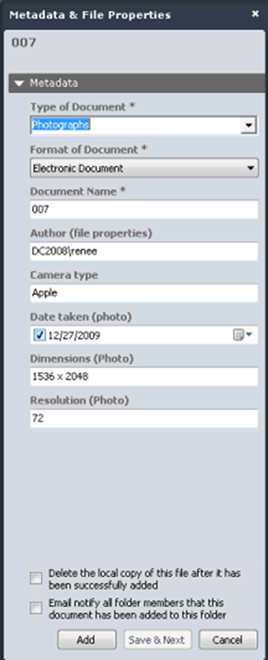
When a document of that schema type is added to the document management system, the document properties will be automatically extracted. In the example below, a jpg document was added to the system using the Photographs schema and the mapped metadata was extracted automatically.
The automatic extraction of properties and conversion to useful metadata in Document Management Software is a valuable tool to speed an organization transition to a paperless office. Once metadata is entered documents can be efficiently organized into virtual folders and become valuable intellectual property
To learn more about the automatic conversion of document properties information into metadata contact [email protected].
Related Article: http://documentmanagementnews.blogspot.com/2011/10/best-practices-for-document-heirarchy.html
To learn more about the automatic conversion of document properties information into metadata contact [email protected].
Related Article: http://documentmanagementnews.blogspot.com/2011/10/best-practices-for-document-heirarchy.html
